
Deploying a large language model (LLM) into a real client workflow is fundamentally different from running a demo. The gap between a convincing proof-of-concept and a production system that handles real users, real data, and real failure modes is where most AI projects stall. This guide documents what that transition actually involves: the infrastructure decisions, the evaluation loops, the compliance checkpoints, and the operational patterns that determine whether an LLM integration ships or gets shelved.
TL;DR
Moving an LLM from prototype to production requires structured evaluation, observability, and rollback capability, not just a working prompt.
Regulated industries (Fintech, Healthcare) introduce compliance constraints that must be designed in from the start, not retrofitted.
A practical CI/CD pipeline for LLMs includes prompt versioning, regression testing, and staged rollouts.
LLMOps in 2026 is a defined discipline with a repeatable roadmap covering data, model selection, evaluation, and scaling.
Teams using tools like Claude and Cursor report delivery acceleration of approximately 30% when AI is embedded across the full software lifecycle.
About the Author: 724SOFTWARE is a Vietnam-based software engineering company and official partner of Claude (Anthropic) and Cursor. The team has hands-on experience integrating LLMs including Claude, Gemini, and LangGraph into production client systems across Edtech, Fintech, and Enterprise platforms.
What Actually Breaks When You Move an LLM to Production?
The failure modes in production LLM deployments are not the ones most teams anticipate. The model itself rarely causes the outage. What breaks is everything around it.
Common production failure points include:
Latency spikes when inference calls block synchronous user-facing requests
Prompt drift when model updates silently change output format or tone
Context window mismanagement causing truncation or incoherent multi-turn responses
Dependency failures when the LLM API is unavailable and there is no fallback path
Cost overruns from unthrottled token usage in high-volume workflows
The honest framing is this: an LLM is a non-deterministic external dependency. Production engineering treats it the same way it treats any third-party service, with circuit breakers, retries, timeouts, caching layers, and monitoring. Teams that skip this framing and treat the LLM as a magic function call will encounter each of these failure modes in sequence.
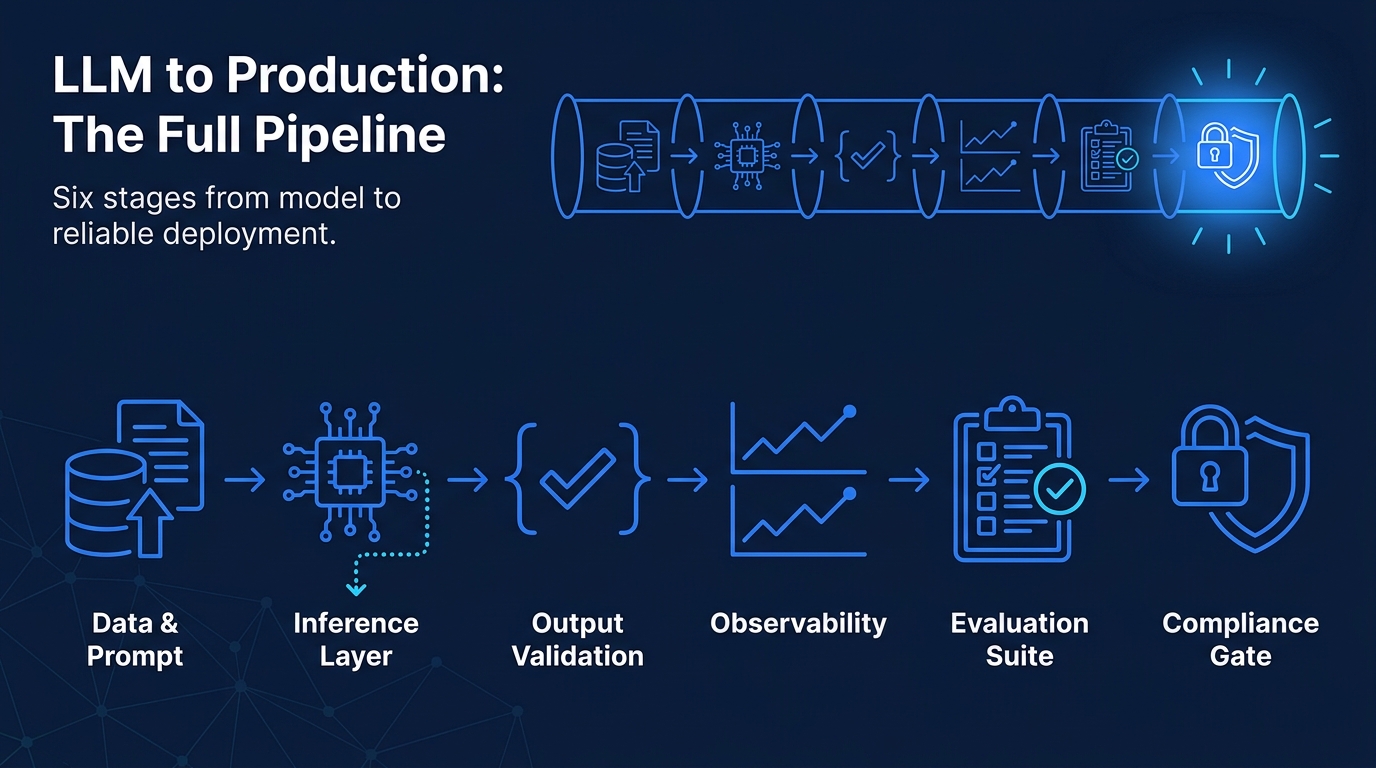
How Should You Structure an LLM Deployment Pipeline?
A production LLM pipeline is not a single inference call. It is a layered system with distinct responsibilities at each stage.
Stage | Responsibility | Key Decisions
|
|---|---|---|
Data preparation | Clean, chunk, and embed context | Chunking strategy, embedding model |
Prompt management | Version and test prompts as code | Prompt registry, variable injection |
Inference layer | Call model, handle retries and fallbacks | Timeout policy, fallback model |
Output validation | Parse, filter, and schema-check responses | Output guards, format contracts |
Observability | Log inputs, outputs, latency, and cost | Tracing tools, cost dashboards |
CI/CD integration | Regression-test prompts before deployment | Eval suites, staged rollouts. |
Each stage requires explicit ownership. In practice, the observability and CI/CD stages are the ones most commonly skipped in early builds, and the ones that cause the most painful rollbacks later.
What Does LLM Evaluation Look Like in Practice?
Evaluation is the discipline that separates teams shipping reliable LLM features from teams firefighting regressions. In 2026, evaluation (evals) is treated as a first-class engineering artifact, not an afterthought.
A practical eval suite for a production LLM feature typically covers:
Functional correctness: Does the output match the expected answer for a golden test set?
Format compliance: Does the output conform to the required schema (JSON, markdown, structured list)?
Refusal behavior: Does the model correctly decline out-of-scope or unsafe requests?
Latency percentiles: Are p95 and p99 latency within the SLA?
Cost per request: Is token usage within the budget envelope?
Critically, eval suites must run automatically in the CI/CD pipeline before any prompt change is promoted to production. Treating prompts as unversioned strings in application code is the single most common process failure in early LLM projects.
What Changes in Regulated Environments Like Fintech or Healthcare?
Stepping back from the technical pipeline, a separate and often underestimated concern is compliance. Regulated industries do not just add audit logging as an afterthought. They change the architecture from the ground up.
Key constraints in regulated LLM deployments:
Data residency: Patient or financial data may not leave a specific jurisdiction. This affects model selection (self-hosted vs. API), embedding storage, and log retention.
Audit trails: Every inference call that influences a regulated decision needs a durable, tamper-evident log of inputs and outputs.
PII handling: Input sanitization must strip or pseudonymize sensitive fields before they reach the model context.
Human-in-the-loop gates: High-stakes outputs (credit decisions, diagnostic suggestions) require a review step before action is taken.
Model explainability: Some regulators require that automated decisions be explainable in non-technical terms.
For teams building in Fintech or Digital Healthcare, these requirements must be part of the initial architecture review, not a compliance retrofit at go-live. ISO 27001:2022 and SOC 2 Type II certification provides a documented framework for handling data security controls in these contexts.
How Do You Scale an LLM Integration Without Rebuilding It?
Building on the evaluation and compliance foundations above, the harder question is operational scaling. An LLM feature that works for 100 users per day may not work for 10,000 without deliberate infrastructure choices.
Practical scaling decisions include:
Async inference queues: Move non-real-time LLM calls off the synchronous request path using job queues.
Response caching: Cache deterministic or near-deterministic outputs (FAQ answers, document summaries) to reduce redundant API calls.
Model tiering: Route simple requests to smaller, faster, cheaper models and reserve larger models for complex tasks.
Horizontal scaling of the inference wrapper: Containerize the LLM service layer so it can scale independently of the core application.
Cost alerting: Set hard budget thresholds per feature and per tenant before scaling, not after.
The LLMOps discipline formalizes these decisions into a repeatable operational loop: deploy, observe, evaluate, tune, and redeploy. Teams that establish this loop early compound their delivery speed over time.
Frequently Asked Questions
What is the biggest difference between an LLM prototype and a production deployment?
A prototype validates that the model can produce useful output. A production deployment adds reliability, observability, versioned prompts, cost controls, and tested failure handling around that output.
How do you version prompts in a production system?
Store prompts in a dedicated registry (a database table or configuration file under version control), inject variables at runtime, and run eval suites against each prompt version before promotion.
Which LLMs are most commonly used in production enterprise workflows in 2026?
Claude (Anthropic) and Gemini are widely used in enterprise contexts for their instruction-following reliability and context-length capacity. Model selection depends on latency requirements, cost, data residency constraints, and task type.
How do you handle LLM failures in a production workflow?
Implement circuit breakers that detect repeated failures, fall back to a secondary model or a deterministic response, and queue failed requests for retry. Never allow an LLM call to be a single point of failure in a user-facing flow.
What observability tools work well for LLM production systems?
Tracing tools that log full prompt and completion pairs, latency metrics broken down by model and prompt version, and cost dashboards per feature and per tenant are the three minimum viable observability layers.
How long does it take to build a production-ready LLM integration?
A well-scoped LLM feature with a defined input/output contract, a golden eval set, and an observability layer typically takes four to eight weeks for a senior engineering team to deploy reliably. Scope creep in the prompt design and compliance requirements are the most common causes of delay.
Does using AI tooling like Cursor or Claude actually speed up LLM feature development?
Yes, in measurable terms. Teams at 724SOFTWARE that apply Claude and Cursor across the development cycle report approximately 30% acceleration in delivery, specifically in code generation, test writing, and documentation tasks that would otherwise consume senior engineer time.
About 724SOFTWARE
724SOFTWARE is a Vietnam-based software engineering company and official partner of Claude (Anthropic) and Cursor. With 200+ professionals, 58% of whom are senior-level engineers, the team delivers production AI integrations, custom software, and dedicated engineering capacity to clients across Singapore, Australia, the US, the UK, and the broader APAC region. Certified to ISO 9001, ISO 27001:2022, and SOC 2 Type II, with GDPR compliance, 724SOFTWARE operates as a long-term technology partner for companies building and operating digital products at scale. A 95% client retention rate reflects the stability of these engagements.
Ready to move your LLM from prototype to production?
Talk to the engineering team at 724SOFTWARE about building a deployment pipeline that works in real client workflows.




